※ 本記事は、Zennへの投稿を再録したものです。オリジナル記事はこちら。
WACK Stack というウェブメディア向けの開発スタックを考えてみました。まだ本番運用はできていませんが、PoC としてプロトタイプを作ってみたところ「いやこれ、マジでかなりいけるんじゃないか?」という感触を得たので紹介したいと思います。
WACK Stack とは、
- WordPress
- Astro
- CDN
- Kysely
のそれぞれの頭文字をとったもので、これらから構成されるスタックに名前を付けたものです。WordPress を CMS として使いながら、パフォーマンスとスケーラビリティに優れ、モダンなスタイルで高速に開発とリリースがしやすいウェブメディアのための構成として考えました。
なお、文中で「中・大規模のウェブメディア」といった曖昧な表現が頻発しますが、ざっくり記事の総数が1万記事以上、月間 PV 数が数千万〜数億くらいのウェブメディアを想定しています。
前置き
CMS として WordPress を採用するメリット
弊社 KODANSHAtech の主な業務の1つにウェブメディアの開発があるのですが、そのときにWordPress を使うことが多いです。
WordPress を採用しておけば、すぐにほぼ完全に日本語ローカライズされた UI を持つオープンソースの CMS が手に入るというのが一番嬉しいポイントで、Bedrock などを利用することで現代的な開発・デプロイのフローにも対応しやすくなっています。加えて、WP REST API や WPGraphQL の活用も一般的になり、ヘッドレス運用がしやすくなったのも採用の後押しとなっています。
また、スペックには現れないですが極めて重要な点として、WordPress は使った経験があるデジタル編集部の編集者やライターが多いということがあります。結局最終的に重要なのは入れる箱ではなく中身たるコンテンツの運用になるので、その入稿業務に入るための学習コストが低いことは業務のスケールの助けとなってくれます。開発面のスケールでも同様に、WordPress であれば、経験や実績のある開発パートナーやフリーランスのエンジニアとも協業しやすいという大きな利点があります。
個人的な話としても、WordPress とは長い付き合いになってきましたが、それでも触っていると今なお新しい発見があったりしてなかなか楽しいです。
WordPress のパフォーマンス問題
ここまで WordPress を使うメリットを書いてきましたが、WordPress のデメリットというのももちろん存在します。というか、それは開発者であれば割と理解している人が多いと思うので、今それをここで羅列するつもりはありません。
が、実際にこれまで、それなりの規模感のウェブメディアで WordPress を運用してきてほぼ毎回苦労していることがあって、それは WordPress のパフォーマンス問題 です。
WordPress はコアの仕組みとして各種処理に対してフックを挿せる機構が用意されており、ユーザーやプラグイン製作者が機能を拡張しやすくなっています。また、WordPress のデフォルトの DB テーブルは非常にシンプルかつ柔軟なパターンに対応できるようになっていて、これらが WordPress の強みになっています。
しかし、実はこれが罠にもなり得る点であって、中規模以上のウェブメディアで無邪気にプラグインを追加したり、テーマのコードで素朴なデータの取得をしていると、ほぼ必ず、運用を続ける過程で以下のような問題にぶつかってしまいます。
- レコード数が想像してる感じよりずっと多い! (
wp_postmetaはあっという間に1,000万レコードになっていることでしょう) - 余計な SQL クエリ、非効率な SQL クエリが発行されまくっている! (WordPress API が発行するクエリはかなり気が利いているが、よく見ると無駄なクエリや、全然インデックス擦ってないクエリとかも多いはず)
- 読み込まれるPHP コード量が肥大化していて、シンプルにアプリケーションとして遅い!
近年では、上記のようなパフォーマンス問題を解決するために CDN を前段に設置するパターンも増えてきました。WordPress は動的にレンダリングされる PHP アプリケーションですが、生成された HTML (やその他アセット) を CDN 経由で配信するようにして、リクエストが WordPress オリジンに届かないようにしてエッジキャッシュで捌くというパターンです。
実際これは強力で、ちゃんと設計できれば実にうまくいきます。しかし…これがうまくいっているのもまた罠になり得ると考えています。ウェブメディアのピーク時の秒間アクセス数というのは割ととんでもない量になります。なので、例えばアクセスが集中しているときに CDN キャッシュが切れていたとしたら… WordPress からのレスポンスをエッジがキャッシュするまでの間のアクセスはすべて、WordPress オリジンへのリクエストとして飛んでいきます。もちろん WordPress 側がすぐにレスポンスを返せれば問題になりませんが、WordPress のイマイチなパフォーマンスを放置し、それを誤魔化すために CDN に頼っていた場合は、こういったビジネス上は大きなチャンスとなるはずの場面で致命的な障害を起こしてしまう可能性があります。まぁ何というか、本当にあった怖い話ってやつですね。また、パフォーマンス面での CDN への依存が大きくなるほど、アプリケーションとしての機能追加や改修のデプロイに非常に神経を使うようになってしまい、高速な開発とリリースを維持するのも難しくなってしまいます。
そもそも動的なレンダリングを避け、Simply Static を導入したり、Jamstack などの静的な構成にする、というアイデアもあります。しかし、あくまで中・大規模なウェブメディアを想定すると、分単位で更新の発生する中でビルドタイムにコンテンツを静的に確定させておくというのは、個人的にはちょっと無理があると考えています。そこで Next.js の ISR の発想などはかなりいい感じの折衷案だと思っていましたが、これもプラットフォームの制限などがあり容易に採用できるものではありません (Next.js は App Router になるとまたパフォーマンス戦略が変わるという別の論点もあります) 。
したがって、上記のような問題を解決するには、結局はちゃんと WordPress のパフォーマンスと向き合い、普通にがんばる。つまり、丁寧にパフォーマンスをプロファイリングしてボトルネックを特定して潰すような対処が必要です。その中では、WordPress の便利な API やプラグインを使うことを諦めて、自前で処理を実装したり生の SQL クエリを書くことを求められることも多いでしょう。
言い換えるとこれは、 サイトの規模が大きくなってくるほど、WordPress エコシステムから得られる恩恵は少なくなり、自分たちで工夫して実装する機会が増える ということが言えると思っています。このことが、これから紹介していく内容についての発想の原点となります。
WACK Stack とは
前置きがだいぶ長くなってしまいましたが、ここからが本題です。ウェブメディアの開発・運用に最高 (かもしれない) WACK Stack というのを考えたので紹介します。
改めてですが、WACK Stack とは、
- WordPress
- Astro
- CDN
- Kysely
のそれぞれの頭文字をとったものです。
WordPress と CDN は前置きでも触れているので改めて説明するまでもないでしょう。CDN に頼るリスクの話をしといて CDN 使うのかよ、と感じるかもしれませんが、過剰に頼りすぎて本体側のチューニングを疎かにしなければこれほど強力なものもありません。
それ以外の Astro と Kyseley については、WACK Stack の話を始める前に軽く紹介しておきます。
Astro
Astro とは JavaScript ランタイムで動作するウェブフレームワークです。レンダリングがサーバーサイドで完結し、クライアント側で動的にしたい部分だけを明示的に指定できるアーキテクチャが特徴です (アイランドアーキテクチャ)。
Astro はデフォルトでは静的サイトジェネレーターとして動作しますが、各種ランタイムに対応する SSR アダプターをサポートしており、例えば、動的にページにレンダリングするサーバーサイドの Node.js アプリケーションとして動かすこともできます。
※このようにサーバーモードで動かしたい場合は、output モードを server に設定します。 https://docs.astro.build/en/core-concepts/rendering-modes/
ウェブメディアの場合は、主にサードパーティスクリプトとの連動などが理由で、CSR (Client Side Rendering) を考慮しなくても済む方が都合が良いことも多く、Astro で構成したサイトが必ず MPA (Multi Page Application) となることはメリットになります。開発時にも、基本すべてサーバーサイドで動作するのでデバッグがしやすいことも利点です。
こういった理由から、WACK Stack のフロントエンドフレームワークとして Astro を採用し、動的なレンダリングのためのサーバーモードを利用します。
Kysely
Kysely とは TypeScript の型安全性をフル活用できるクエリビルダーライブラリです。
ORM として Prisma を使ったことがある人は多いだろうと思います。要はあの、クエリの結果やクエリ API の呼び出しが TypeScript によって型安全になる…それのクエリビルダー版と想像してもらうとイメージはしやすいかなと思います。
Kysely は MySQL にも対応しており、外部で生成される DB スキーマが存在する場面でも使いやすいため、WACK Stack では、フロントエンドから DB にアクセスするためのライブラリとして採用します。
…はい、そうです。WACK Stack ではフロントエンドが WordPress の DB に直接接続するのです。
WACK Stack の構成
WACK Stack の基本的な構成は以下のようになります。
- CMS アプリケーション: WordPress
- フロントエンドアプリケーション: Astro
- データベース: MySQL
- CDN: Cloudflare, CloudFront など
全体的には一般的なヘッドレス WordPress 構成とほぼ変わりません。CMS としての WordPress アプリケーションとその DB があり、フロントエンドのアプリケーションがあり、静的にキャッシュするための CDN がある、という構成です。
特殊なのは Astro フロントエンドから Kysely を使って DB に直接アクセスするという点になります。とはいえ、このように「WordPress を使いつつ、フロント側ではパフォーマンス最適化のために WordPress を介さずに DB のデータを使う」というアイデア自体はそれほど珍しいものではありません。まぁ誰でも一度は思いつくよな、ということもありますし、実際にいくつかの先行事例を見聞きしたこともあります。
しかし現実にはこれは口にするほど簡単ではないです。WordPress のデータは、「普通の」ウェブアプリケーション的な見方だと「超ゆるゆる」なデータになっています。データモデルが RDB スキーマとしてきっちり設計されており、RDB の制約によってデータの整合性が保たれている…といったことは全くないと思ってください (テーブルを自前で用意して使うなどで、厳密に整合性を保つ設計にすることが不可能なわけではありませんが、WordPress を「普通に」使うとそうはなりません) 。入力の際のバリデーションなどもしっかり作り込めているケースの方が稀だと思うので、つまるところ WordPress のデータに関して、その整合性は全然信用できない前提で考えるしかないのです。
WordPress コアや人気のプラグインの API は、この緩いデータに対してうまいこと辻褄を合わせたり安全に扱えるように工夫がされています。しかし、これは逆から見るとその分の処理のオーバーヘッドが発生しているということで、まさにこれはパフォーマンス劣化の要因の1つになっています。
Kysely による TypeScript 型安全性
Kysely を使うと、DB クエリやその結果を TypeScript で型安全に扱えると書きました。これが、前項で言っていた WordPress の緩いデータを扱う上で非常に心強いサポートとなってくれます。
例えば、WordPress のデータを生の SQL クエリで効率的に取得しようとする場合、ほぼ必ず多重にテーブルを JOIN することになります。各テーブルが外部キー制約などによって整合性を維持できているわけではないので、必要なデータをある程度の一貫性がある形で取得するためには OUTER JOIN を使う場面が多くなり、結果として、取得したデータのリレーションには NULL のカラムが含まれることが頻発します。
Kysely が生成する TypeScript 型は賢く、こういったケースで NULL になる可能性のあるプロパティの型は string | null のようなユニオン型になります。これによって、アプリケーション側で適切にチェックしてハンドリングすることを強制できて、ランタイムでデータの状態によっていきなり例外が発生する系の障害を防ぐのにかなり役立ちます。
また、Kysely のエコシステムには TypeScript の型コードジェネレーター (CodeGen) があり、MySQL のテーブルに対して introspection を行うことで型定義ファイルを生成することができるため、WordPress が作った DB スキーマを自分で TypeScript 型にマッピングしていく必要もないです。これももし自前で用意してメンテするのであれば、つらみと潜在バグの温床になってしまうことが想像できます。
このように、Kysely を使うことで、WordPress のデータを外部から直接扱うことのハードルをかなり下げることができると考えます。
もちろん、Kysely によってデータスキーマ上の型安全性が得られたとしても、データそのものを保証するのは開発者自身になります。例えば、文字列として取得したデータは、本当に単純な文字列かもしれませんし、シリアライズされた PHP オブジェクトかもしれません。幸い Node.js には php-serialize パッケージもあるので、シリアライズされた PHP オブジェクトのパースをライブラリに任せることが可能です。しかし、丁寧にデータのチェックや例外のハンドリング処理を仕込んで、その文字列が本当に PHP オブジェクトであることを確認すること、そして、期待通りのデータではなかったときにどう扱うのかの仕様を決めるのはアプリケーション開発者の責任になります。
システム構成図
以下が WACK Stack の基本的なシステム構成図です。とりあえず手元にあった AWS 用のアイコンを利用しましたが、同様の構成であれば特にプラットフォームの制限などはありません。
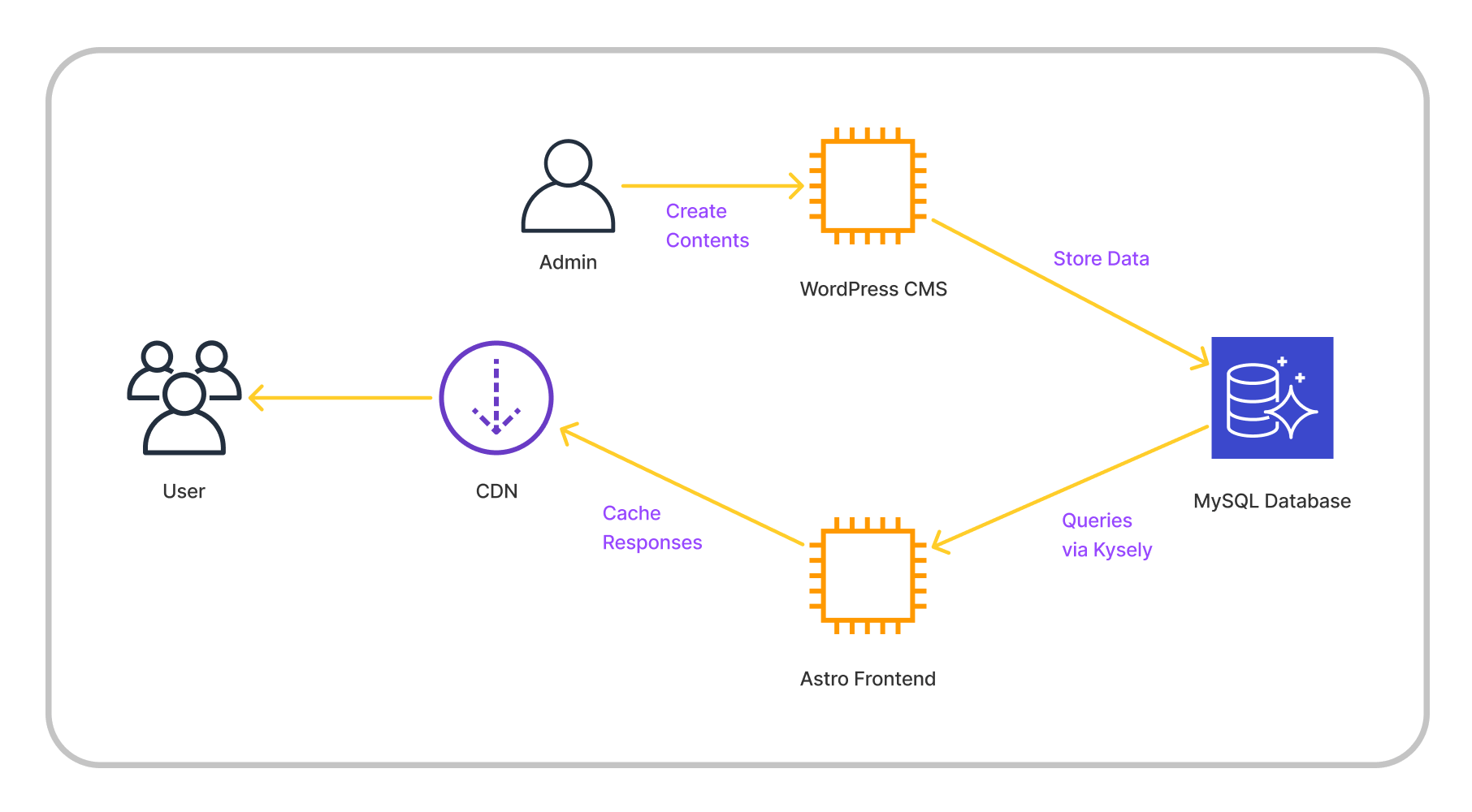
…うむ、別に面白くもなんともありませんね。これまで書いた内容をただ図にしただけです。
これだけだとマジで何も面白くないのですが、WACK Stack の特徴として、現実世界で戦っていくためにとても有効な、以下のような構成をごく自然に実現しやすいというところを推したいです。
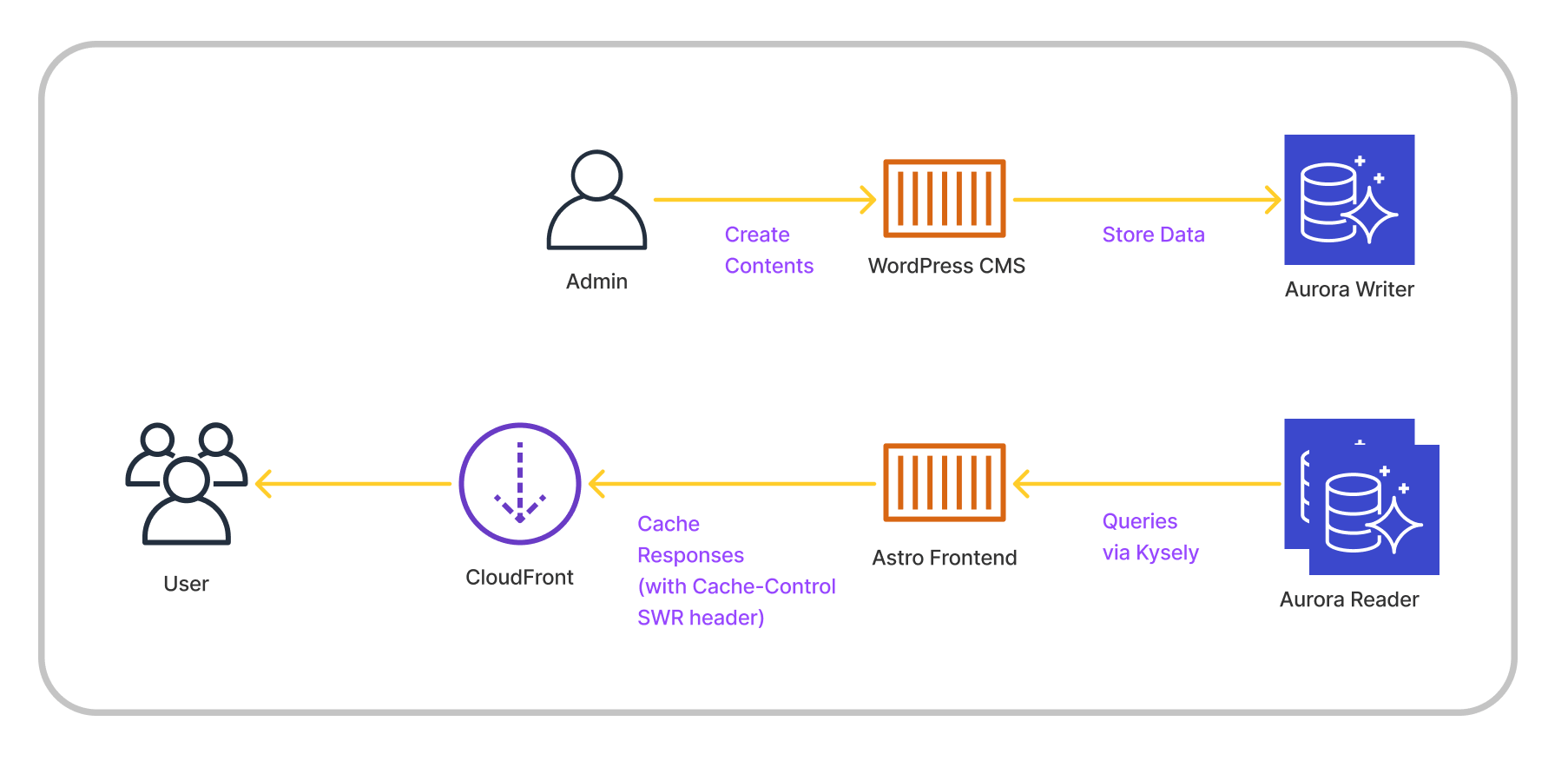
現実世界を想定した話なので、こちらは弊社でメインに使っている AWS での構成例になっています。
ウェブメディアの設計では、書き込みと読み込みが明確に分離することがほとんどなので、意識せずとも CQRS に接近した作りになっていることが多いと思います。WACK Stack の場合は、さらに DB に接続するアプリケーションそのものが分離するので、Amazon Aurora MySQL を使う前提であれば、特に工夫しなくてもデータソースまで分離したアーキテクチャを難なく実現できます。クラスタの同期は Aurora に任せておけばよいですし、アクセス集中などで DB 負荷が高くなったときには単純に Reader インスタンスをスケールアウトすれば良いだけです。
また、Astro がシンプルにページ単位でレンダリングされる MPA であることで、昨年 CloudFront でもサポートされるようになった Cache-Control ヘッダーの stale-while-revalidate ディレクティブを直感的にわかりやすい形で活用しやすいです。記事の更新時などのキャッシュクリアは CloudFront の invalidation に頼ってしまうことになるかもしれませんが、来訪するユーザーに対してかなり高確率のキャッシュヒットを狙えます。Remix や Next.js (Pages Router) でも同様のことは可能ですが、SSR 時の HTML キャッシュと CSR 時のデータキャッシュ両方の考慮が必要になるなど、一段複雑で直感的ではない設計と運用が必要になります。
このように、WACK Stack では、最初からあまり意識せずに構築しても自然に、瞬間的なアクセス集中への対処や、事前に予期される負荷上昇に対してのスケールアウトの準備などがしやすい構成になってくれる、というのが推しポイントです。これらは、特にウェブメディアの運用で求められる特性であると同時に、初期的には非常に見積もりにくくて苦労する、将来的なスケールまで考えた設計に対して、悪くないコスパでスモールスタートしやすいということでもあります。
WACK Stack の実装例
ここまで、WACK Stack の構成や特徴について説明してきました。WACK Stack はあくまでも「組み合わせ」を提案するもので、それぞれの具体的な実装については個々の要件に応じて自由にやってもらえれば良いと思っています。実装例については、プロトタイプとして作ったものの GitHub リポジトリを最後に掲載するので、そのコードを直接見てもらうのも良いでしょう。
しかし、この構成の肝となる、Astro フロントエンドから Kysely を使ってデータを取得する箇所については、せっかくなのでこれから具体的なサンプルコードを掲載します。これは、WordPress の緩いデータに外部から向き合うにあたって試行錯誤しつつ考えてみたコードベース設計の提案でもあります。
サンプルコードで実現したい要件
記事ページを表示するために、ある特定の記事のデータを取得して、画面表示用のデータとして準備して記事画面に渡す、という例で要件を考えます。
- ID で指定した記事データを取得する
- 画面には、記事のタイトル、本文、公開日時、アイキャッチ画像、カテゴリー、description を表示する
- 記事には単一のカテゴリーが紐づいているとする
- description は Advanced Custom Fields (ACF) という定番プラグインで定義したカスタムフィールド (テキストフィールド)。設定されていないケースも許容し、その場合は単純に表示しないこととする
記事用の型の定義
早速 Kysely でデータを取得していきたいのですが、その前に、記事データに対応する汎用的な型を定義します。設計上は記事の「モデル」として機能することを意図しています。これを用意することで、今後記事の一覧ページなどを作るときにも再利用できます。
frontend/src/types/Post.ts
export type Category = {
id: number;
name: string;
slug: string;
};
export type Post = {
id: number;
title: string;
content?: string;
publishedAt: Date;
modifiedAt: Date;
thumbnailPath?: string;
description?: string;
category?: Category;
};
- 記事にはカテゴリー情報も含めたいので、独立した型として
Categoryを定義した上でPostに含めています thumbnailPathはアイキャッチ画像のパスです。このモデルの型では URL ではなく相対パスだけを保持します。これは、画像は画像配信 CDN や S3 経由で配信することも多く、そういった場合を想定すると後から仕様に応じて完全な URL を構成する方が都合がよいためです
何度も言っている「WordPres のゆるゆるなデータ」を象徴するように、optional なプロパティが多くなっています。一般的なアプリケーション開発のモデルとしては微妙ですが、とりあえずここでは、汎用的に扱える最低限の型としてこう定義しています。固く型を定義しようとすると実際の DB 上のデータとの乖離が大きく出てしまうし、再利用性も低くなってしまうので、ベースとなるモデルの型としてはむしろこれくらいの方が適当だと思います。
データ取得のための Kysely クエリを作成する
いよいよデータ取得のための Kysely クエリを作ります。Kysely は処理をメソッドチェーンでつなげていくことで DSL 的にクエリを構築していきます。
クエリの実行は、構築したクエリに対して execute() メソッドを呼び出すことで行いますが、ここではまずクエリの構築だけを行うモジュールを用意します。これは、後からテストを行う際に、ファイルを分けたモジュールでクエリを定義しておいた方がモック化しやすく、実際に DB にアクセスしないロジックのみのテストが書きやすくなるためです。
frontend/src/adapter/database/queries/post-detail.query.ts
import { db } from "../db";
/**
* 投稿に必要な詳細データを取得するクエリ
* 引数の ID で指定した1件の投稿のデータを取得する
* クエリの結果には以下のデータを含む
* - id: 投稿のID (wp_posts.ID)
* - title: 投稿のタイトル (wp_posts.post_title)
* - content: 投稿の本文 (wp_posts.post_content)
* - publishedAt: 投稿の作成日時 (wp_posts.post_date)
* - modifiedAt: 投稿の更新日時 (wp_posts.post_modified)
* - thumbnailPath: サムネイルのパス (JOIN して wp_postmeta の _wp_attached_file から取得したもの)
* - descriptionMeta: 投稿の説明 (ACF の description フィールド) テキストで格納されている前提
* - categoryId: カテゴリーのID (wp_terms.term_id)
* - categoryName: カテゴリーの名前 (wp_terms.name)
* - categorySlug: カテゴリーのスラッグ (wp_terms.slug)
* @param id
* @returns Kysely のビルドしたクエリオブジェクト
*/
export const postDetailQuery = (id: number) => {
return (
db
.selectFrom("wp_posts as posts")
// サムネイルの取得
.leftJoin("wp_postmeta as thumbnailMeta", (join) =>
join
.onRef("thumbnailMeta.post_id", "=", "posts.ID")
.on("thumbnailMeta.meta_key", "=", "_thumbnail_id"),
)
.leftJoin(
"wp_posts as thumbnailPosts",
"thumbnailPosts.ID",
"thumbnailMeta.meta_value",
)
.leftJoin("wp_postmeta as thumbnailAttachedFileMeta", (join) =>
join
.onRef("thumbnailAttachedFileMeta.post_id", "=", "thumbnailPosts.ID")
.on("thumbnailAttachedFileMeta.meta_key", "=", "_wp_attached_file"),
)
// ACF の description フィールドの取得。
// description にはテキストがそのまま入っていることを前提とする
.leftJoin("wp_postmeta as descriptionMeta", (join) =>
join
.onRef("descriptionMeta.post_id", "=", "posts.ID")
.on("descriptionMeta.meta_key", "=", "description"),
)
// カテゴリーの取得
// カテゴリーは1つのみ設定されていることを前提とする
.leftJoin(
"wp_term_relationships as termRelationships",
"termRelationships.object_id",
"posts.ID",
)
.leftJoin("wp_term_taxonomy as termTaxonomy", (join) =>
join
.onRef(
"termTaxonomy.term_taxonomy_id",
"=",
"termRelationships.term_taxonomy_id",
)
.on("termTaxonomy.taxonomy", "=", "category"),
)
.leftJoin("wp_terms as terms", "terms.term_id", "termTaxonomy.term_id")
// where
.where("posts.ID", "=", id)
.where("posts.post_type", "=", "post")
.where("posts.post_status", "=", "publish")
// select する対象
.select([
"posts.ID as id",
"posts.post_title as title",
"posts.post_content as content",
"posts.post_date as publishedAt",
"posts.post_modified as modifiedAt",
"thumbnailAttachedFileMeta.meta_value as thumbnailPath",
"descriptionMeta.meta_value as descriptionMeta",
"terms.term_id as categoryId",
"terms.name as categoryName",
"terms.slug as categorySlug",
])
);
};
いきなりだいぶ長いコードになりましたが、クエリビルダーの API としては素直でわかりやすい記述ですね。ただ記事1つのデータを取得するだけでこんな長いクエリになっちゃうところが WordPress の特徴でもあるのですが、少なくとも WordPress 経験者の方であればここでやっていることの内容も掴めるかと思います。実際に実行されるクエリを確認したければ、この戻り値の結果を .compile() するとクエリ文字列が取得できます。
実際自分で触っていて最初にちょっとわかりにくかった点としては、JOIN するときの .on と .onRef の違いでしょうか。.on で条件に含めたものは単純な文字列として評価されますが、.onRef の場合は実際のテーブルのデータを参照した値になります。例えば、.onRef("descriptionMeta.post_id", "=", "posts.ID") としている箇所を .on にしてしまうと、descriptionMeta.post_id や posts.ID という文字列リテラルとして条件が評価されてしまい、正しい結果が得られません。
また、ファイルが adapter/database 配下のディレクトリに格納されていることにも触れておきます。これは、DB アクセスに関する箇所は全てアダプターとして扱うことで、もし将来的に「やっぱ REST API でデータを取得したいっすわ」といった展開になってしまったときにも、アダプターだけ差し替えることができるようにこうしています。これはまぁ好みの問題かもしれませんが、クリーンアーキテクチャなどを読んだことがある人にはお馴染みの考え方だと思います。
クエリを実行してモデル型を返すリポジトリを作成する
用意したクエリを実行する層としてリポジトリを作成します。リポジトリは以下の役割を持ちます。
- クエリを実行してデータを取得する
- 取得したデータをモデル型 (今の例では
Post) にマッピングする
つまり、リポジトリがモデル型を返すことを保証することで、リポジトリの外側では、DB 上の実体データのあり方を意識することなく、モデル型のことだけを考えればいいようになります。言い換えると、WordPress のゆるゆるなデータに対してのリポジトリ層の責務は、モデル型を返すインターフェースを強制し、それ以外のデータの状態を隠蔽することになります。
frontend/src/adapter/database/post.repository.ts
// 強制するインターフェース
// 本来は別のファイルに定義する
export interface IPostRepository {
findOne(id: number): Promise<Post | null>;
}
// リポジトリの実装
export class PostRepository implements IPostRepository {
async findOne(id: number): Promise<Post | null> {
const postsData = await postDetailQuery(id).execute();
// データが見つからない場合は null を返す
if (postsData.length === 0) {
return null;
}
const postData = postsData[0];
// Category オブジェクトを生成
const category: Category | undefined =
postData.categoryId && postData.categoryName && postData.categorySlug
? {
id: postData.categoryId,
name: postData.categoryName,
slug: postData.categorySlug,
}
: undefined;
return {
id: postData.id,
title: postData.title,
content: postData.content !== "" ? postData.content : undefined,
publishedAt: postData.publishedAt,
modifiedAt: postData.modifiedAt,
thumbnailPath: postData.thumbnailPath || undefined,
description: postData.descriptionMeta || undefined, // プレーンテキストなのでそのままセット
category,
};
}
前項で定義した postDetailQuery の結果を取得し、それを Post 型にマッピングして返しているのがわかると思います。
ID で指定して取得する仕様のため、当然その ID のデータが見つからない場合もあります。そのとき、Kysely クエリの結果としては SQL 同様に結果が空っぽのセット (配列) になりますが、アプリケーション的に扱いやすいように、その場合は null を返すようにしています。
これで、DB 上のデータのあり方についてリポジトリ内にうまいこと隠蔽することができました。
Vitest の機能を使って Kysely のクエリオブジェクトをモック化すれば、以下のように DB 接続を伴わない形でリポジトリのユニットテストを書くこともできます。オブジェクトのマッピングロジックを実際に動かしつつ TDD 的に開発したり、実データでは確認しにくいもの、例えばクエリ結果で null のプロパティが返ってくるエッジケースの取りこぼしがないようにしたいときなどに便利です。
frontend/src/adapter/database/post.repository.test.ts
import { describe, expect, test, vi } from "vitest";
import { PostRepository } from "./post.repository";
describe("PostRepository", () => {
describe("findOne", () => {
test("should return post object", async () => {
// Mocking query
vi.mock("./queries/post-detail.query", async (importOriginal) => {
const mod =
await importOriginal<typeof import("./queries/post-detail.query")>();
return {
...mod,
postDetailQuery: vi.fn().mockReturnValue({
execute: async () => {
return [
{
id: 1,
title: "Title 1",
publishedAt: new Date("2024-01-01 01:00:00"),
modifiedAt: new Date("2024-01-01 02:00:00"),
thumbnailPath: "images/thumbnail1.jpg",
descriptionMeta: "Description 1",
categoryId: 1,
categoryName: "Category 1",
categorySlug: "category-1",
},
];
},
}),
};
});
const repository = new PostRepository();
const result = await repository.findOne(1);
expect(result).not.toBe(null);
expect(result?.id).toBe(1);
expect(result?.category?.id).toBe(1);
});
});
});
画面に表示するためのデータを準備する
先ほど、モデルとなる Post 型について以下のように書きました。
何度も言っている「WordPres のゆるゆるなデータ」を象徴するように、optional なプロパティが多くなっています。一般的なアプリケーション開発のモデルとしては微妙ですが、とりあえずここでは、汎用的に扱える最低限の型としてこう定義しています。固く型を定義しようとすると実際の DB 上のデータとの乖離が大きく出てしまうし、再利用性も低くなってしまうので、ベースとなるモデルの型としてはむしろこれくらいの方が適当だと思います。
しかし、実際の画面上では、
- この optional なプロパティは表示されないので
undefinedであっても問題ないですよ - こっちの optional なプロパティは表示するので
undefinedでは困るんですよ!
という状況が発生します。
これに対して、もちろん、表示する画面の側で例えば以下のようにチェックして表示を制御することも可能です。
{post.category && <p>{post.category.name}</p>}
しかし、これは表示するビューに責務を押し付けていてメンテしにくくなる予感がすごいし、何よりテストがしにくいのです。
...実際、Astro で開発していると、ページやコンポーネントのユニットテストがしにくいという課題を感じます。フレームワークの性質的に E2E テストでがんばってくれ、ということだと思うのですが、今回は Astro アプリケーションが DB を扱い、さらにその対象が「WordPress のゆるゆるデータ」になるので、できるだけユニットテストを手厚くしておきたい気持ちがあります。
したがって、画面に対して直接 Post 型を渡すのではなく、画面専用の型のデータを用意する層を別途作ります。ここでは、各画面をアプリケーションのユースケースであると捉えて、そのユースケース単位で必要なデータを用意するクラスとして定義し、そのクラスに対してテストが書きやすいような作りにしようと思います。
もう一度要件を振り返ってみましょう。
- 画面には、記事のタイトル、本文、公開日時、アイキャッチ画像、カテゴリー、description を表示する
- 記事には単一のカテゴリーが紐づいているとする
- description は Advanced Custom Fields (ACF) という定番プラグインで定義したカスタムフィールド (テキストフィールド)。設定されていないケースも許容し、その場合は単純に表示しないこととする
つまり、これらのデータを過不足なく用意することができれば良いわけです。
画面 = ユースケースとして扱っているので、実際のページのためのファイル、つまり pages/post/[id].astro から利用されることを想定して、以下のようなクラスを定義します。
frontend/src/usecases/post/[id]/get-post-detail.usecase.ts
export type PostForPostDetail = Pick<
Post,
"id" | "title" | "publishedAt" | "description"
> & {
content: string;
thumbnailUrl: string;
category: Category;
};
export class GetPostDetailUseCase {
constructor(private readonly postRepository: IPostRepository) {}
async execute(id: number): Promise<PostForPostDetail> {
const post = await this.postRepository.findOne(id);
if (!post) {
throw new NotFoundError(`Post (id: ${id}) is not found.`);
}
// content が string であることを保証する (空文字列は許容する)
const content = post.content ?? "";
// thumbnailUrl を設定する
// thumbnailPath から実際の URL を構成する
const postWithThumbnailUrl = `https://example.com/${post.thumbnailPath}`;
// category が設定されていない場合は想定外のデータなのでエラー
if (!postWithThumbnailUrl.category) {
throw new CategoryNotSetError(`Post (id: ${id}): Category is not set.`);
}
return {
id: postWithThumbnailUrl.id,
title: postWithThumbnailUrl.title,
content,
publishedAt: postWithThumbnailUrl.publishedAt,
thumbnailUrl: postWithThumbnailUrl.thumbnailUrl,
description: postWithThumbnailUrl.description,
category: postWithThumbnailUrl.category,
};
}
}
まず、必要なデータを過不足なく用意した PostForPostDetail 型を定義しています。Post 型では optional 扱いだったプロパティについても、要件レベルで必須としていない description 以外のものはすべて必須なプロパティとして再定義しているのがわかると思います。
GetPostDetailUseCase では、PostRepository から Post 型のデータを取得して、PostForPostDetail 型にマッピングして返すようにしており、アイキャッチ画像の完全な URL への変換もそこで行なっています。カテゴリーは必須としているので、存在しない場合は想定外のエラーとして扱いたいため、もし取得したデータにカテゴリーが含まれていない場合はカスタムエラーを投げるようにしています。
また、内部で利用するリポジトリはコンストラクターで DI するようにしているので、リポジトリのテストのときのように Vitest のモック機能を使わなくても、以下のように簡単にテスト時にモックを差し込むことができます。
frontend/src/usecases/post/[id]/get-post-detail.usecase.test.ts
import { describe, expect, test } from "vitest";
import type { Post } from "../../../types/Post";
import { GetPostDetailUseCase } from "./get-post-detail.usecase";
describe("GetPostDetailUseCase", () => {
describe("execute", () => {
test("should return PostForPostDetail object", async () => {
const repository = {
findOne: async (): Promise<Post | null> => {
return {
id: 1,
title: "Title 1",
content: "Content 1",
publishedAt: new Date("2024-01-01 01:00:00"),
modifiedAt: {} as any,
thumbnailPath: "images/thumbnail1.jpg",
description: "Description 1",
category: {
id: 1,
name: "Category 1",
slug: "category-1",
},
};
},
};
const useCase = new GetPostDetailUseCase(repository);
const result = await useCase.execute(1);
expect(result.id).toBe(1);
expect(result.title).toBe("Title 1");
expect(result.content).toBe("Content 1");
expect(result.publishedAt).toEqual(new Date("2024-01-01 01:00:00"));
expect(result.thumbnailUrl).toBe(
"https://wp.example.com/app/uploads/images/thumbnail1.jpg",
);
expect(result.description).toBe("Description 1");
expect(result.category.id).toBe(1);
expect(result.category.name).toBe("Category 1");
expect(result.category.slug).toBe("category-1");
});
});
});
これで、画面に表示するためのデータを保証することもできました。リポジトリ層との責務の分離も明確で、アプリケーション全体の見通しも良い感じです。
このように処理の層を分けるのは、開発時は余計な手数が多くて面倒に感じるかもしれませんが、将来的に更なる高パフォーマンスを狙ってアプリケーション側でキャッシュを導入するときにも役に立ちます。データをキャッシュする層が明確になるので、アプリケーションでメモ化したり Redis などを使ってキャッシュするときに、リポジトリ層が返却するデータをキャッシュするとか、ユースケース層が返却するデータをキャッシュするとかといった一貫性のある設計がしやすくなります。
画面の構築
実際の画面の構築は、一般的に Astro を使う場合と違いがないので簡単にいきます。以下のように、単純にコンポーネントスクリプト内でユースケースを実行し、取得した post データを元に画面を構築すればよいだけです。post の型は当然、ユースケースで定義した PostForPostDetail 型になるので、必要なデータは揃っているはずです。
pages/post/[id].astro
---
// ...省略
const id = parseInt(Astro.params.id, 10);
const useCase = new GetPostDetailUseCase(new PostRepository());
const post = await useCase.execute(id); // 実際にはエラーハンドリングなども行う
// ...省略
---
<main>
<h1>{post.title}</h1>
// ...省略
</main>
まとめ
WordPress のパフォーマンス問題への向き合い方として、フロントエンドが直接 DB にアクセスするという方法は以前から考えていましたが、Kysely を使ってみたことで現実味が高まったと感じて、このように1つの開発スタックの提案としてまとめてみました。
自然とスケーラビリティの高いシステム構成がしやすいなど、当初は想定していなかった美味しいところも見えてきて、かなり現実的に使えそうな構成になっていると考えています。早く本番で採用してみたいですね。
プロトタイプのソースコード
今回プロトタイプとして作ったものは GitHub に公開しています。
https://github.com/5t111111/wak-stack
(wack-stack ではなく) wak-stack という名前のリポジトリになっているのは、間違いではなく意図したものです。というのは、このリポジトリにはアプリケーションコードのみが含まれており、CDN の構成は含まれていないためです。
元々はこのリポジトリの内容に加えて、AWS CDK で構成した AWS インフラ用のコードも含まれていたのですが、そこには微妙にパブリックに公開しにくいデータも含まれていたので、今回はアプリケーションコードのみを公開することにしました。だから WACK の C は抜きになっています。
FAQ
最後に、WACK Stack についてよくある質問についてまとめておきます。
いや、もちろんまだ誰にも質問されてないけど、質問されそうなことを勝手に先周りして回答します。
Kysely じゃなくて Prisma じゃダメなの?
WordPress のテーブルを Prisma の schema.prisma として定義して、Prisma を利用して DB アクセスする…確かにこれでもうまくいきそうに思えます。というか、実際やってみたこともあります。
しかし、Prisma の API で WordPress のデータを扱うのは、QoL が低いというか DX が微妙すぎるというか、とにかく苦行に近いものになってしまうと思います。Prisma はとても素晴らしいですが、ぶっちゃけこの用途には向いてません。やっぱり Prisma が力を発揮するのは ORM として扱いやすいデータモデリングありきだと思います。
もちろん Prisma でも不可能ではないですが、頑張って書いたクエリの記述も、それが何をやりたいことなのかも把握しにくい、非常に宣言的に見えないコードになってしまいます。「普通に SQL 書かせてくれ」という気持ちになることでしょう。
Kysely は SQL を書くのに近い感覚で書けるので、静的に型チェックをしたいということと、ユースケースに対応する SQL を自由に書きたいということのバランスがかなりよい塩梅になっていると感じます。
WordPress 側の構成がかなり制約されるのでは?
はい、その通りです。例えば本番環境で自由にプラグインを導入したり、カスタムフィールドを追加したりといった運用は一切できなくなると考えてよいです。
しかし、自分の考えでは、長期的に運用していく WordPress であれば、WACK Stack を使う使わないに関係なく、上記のような運用はしない方が良いと思っています。
Bedrock などを使ってプラグインのインストールを制限したり、カスタムフィールドも ACF の Local JSON 機能などで必ず開発環境で検証した上でリリースすべきです。固定ページの追加などもできるだけ同様のフローで行うのがよいと考えています。
理由は、プラグインへの依存が増えたり、データベース上にしか存在しない仕様が発生すると、メンテナンスが非常に困難になり、バージョンアップなどで大きな障害になるためです。結果的にはメンテナンスに対して腰が重くなり、それはそのままセキュリティリスクにも繋がってしまいます。
また、本記事のテーマでもあるパフォーマンスの話で言うと、データ量の増大に伴ってサイトが遅くなったときに、プラグインが発行するクエリに合わせる形でテーブルにインデックスを貼る、ということもよくやると思います。これ自体は間違いなく正攻法のアプローチなのですが、アドホックにやりすぎると、いわゆる「闇雲インデックス」に近い状態になってしまいますし、そのプラグインが提供してくれた価値と天秤にかけたときに本当に妥当な設計になっているかどうか疑問なケースも増えてくると思います。
WordPress エコシステムのメリットを潰してしまうことにはなりますが、究極的には WordPress コア以外はすべて自前で実装する勢いでもいいと思っています。そして、本当に共通化できるロジックだけプラグインとして切り出す。嬉しいことに、実装の参考にできるソースコードはそれこそ星の数ほど見つかるし、ChatGPT さんも WordPress についてはやたら詳しいので…
既存の WordPress サイトを WACK Stack に移行できる?
正直、かなり難しいと思います。もちろん不可能ではないですが、直前に書いたように、WordPress にかなり自覚的な制約が求められるため、そうではない状態で運用されてきたサイトの移行には適していません。
例えば、初期設計の段階から、外部からクエリされることを意識して ACF のフィールド名が wp_postmeta テーブル内で一意に定まるようにしていないと、フィールド名の衝突により意図した結果が得られないといった問題が考えられます。それをクエリする側の実装によって避けるには、ACF そのものに近いような実装、つまり完全に車輪の再発明をするような作業が必要になり、WACK Stack なんか使わない方がマシという結果になりそうです。
したがって、どちらかというと、このスタックは新規で WordPress を使ってサイトを作るときの選択肢の1つと考えています。
ですが、これも WACK Stack を使う使わないは置いといて、外部から直接クエリされることについては最初から意識しておいて損はないと思っています。ウェブメディアであっても、一定規模のものになると BI ツールや BigQuery への連携が求められる場面が出てくるので、そのときに WordPress やプラグインの提供する API にべったり依存していない方が都合がよいことも多いためです。
小規模のサイトの構築でも使える?
使えるか使えないかで言えば、もちろん使えます。
ですが、例えば VPS 1台で運用が回るようなサイトで WACK Stack を使う理由はほぼ無いでしょう。単純に、ランニングコストだけで最低でも数倍以上になるだろうし、WordPress の運用に求められる制約に対して得られる恩恵が割に合わないと思います。
ただ、小規模のサイトであっても、WordPress はヘッドレスに使うことが前提で、それを少人数のチームで高速開発したい場合などは検討に値すると考えています。
少人数で高速開発する場合、WordPress 側はできるだけローコードで済ませたくて、そのために銀の弾丸的に WPGraphQL を導入するケースが多く見られます。これは設計上はエレガントに感じるのですが、残念ながら WPGraphQL は決して速くないので、相当注意深く使わないと、データ量がそんなに多くない状態でもパフォーマンス不安が発生します。実際に、まだローンチすらしていない段階から「サイトが重い!」と言われて、結局パフォーマンス対策に工数がかかってしまうプロジェクトを見てきました。
WACK Stack であれば、WordPress 側ではデータ取得を行わないので、WordPress のコードは極端にローコードに抑えておくことができます。そして、クライアント側のユースケースに合わせてフロントエンドで最小限のデータ取得をすれば良いので、よほど常識外れのクエリを書いたりしなければ、こういったパフォーマンス懸念はほぼ発生しません。
フロントエンドの開発に SQL やバックエンド的な設計が求められることになるんじゃないの、という意見もあると思います。まぁ、昨今のフロントエンドエンジニアはサーバーサイドに足を突っ込むことを余儀なくされているので、きっとそこは大丈夫じゃないですかね… というのは置いておいて、プロトタイプの実装例のようにアプリケーションに明確な層を定義して分離しておけば、この構成が問題になることは少ないと思います。例えば、普段バックエンドの REST API ができるまでは一旦スタブを置いて先に画面作っとく、みたいな感じでユースケース層をスタブ実装にしておくなど、一般的なフロントエンド分離構成のときと同じように工夫すれば問題ないでしょう。
Astro ではないフロントエンドのウェブフレームワークを使ってもいいの?
はい、もちろんです。特に Astro を採用している理由は本文中に書いた通りですが、Next.js でも Remix でも、サーバーサイドだけで動作するロジックを書けるフレームワークであれば何でも使えます (ただし、Next.js App Router の場合は、フレームワークのカスタム fetch への依存が大きいので、Route Handlers で定義した API を経由してあげるなどの工夫が要りそう)。
おまけですが、特に Node.js のフレームワークを使うというのにはもう1つ利点があって、それは Gutenberg のパーサーに JavaScript 実装が用意されていることです。これによって DB から取得した記事本文をオブジェクトにパースすることができるので、画面上に本文を表示するのに dangerouslySetInnerHTML 的なものを使わない選択肢を持ちやすくなります。
フロントエンドの設計はいつもと同じでいいの?
はい。いつも通りに設計してください。コンポーネントの設計などは WACK Stack であっても一切何も特殊なことはありません。
また、例えば React アプリケーションで、API 疎通をする箇所やライブラリに依存する箇所ではカスタムフックを使って腐敗防止層を作っておくような設計をすることも多いと思います。ここまでに WACK Stack のプロトタイプの実装例として紹介してきたリポジトリだユースケースだの設計も、それと基本的にやりたいことは同じで、ただ実装方法が異なるだけだと考えて良いと思います。
stale-while-revalidate ディレクティブを使いやすいと書いてあったが、Cache-Control ヘッダーはどう設定するの
まず、これは SSR アダプターを使っている前提での話になりますが、Astro でレスポンスヘッダーに Cache-Control ヘッダーを設定する方法は様々です。
WACK Stack のプロトタイプ実装で利用している @astrojs/node アダプターに限定しても、スタンドアローンのサーバーを使っている場合と Express などのカスタムサーバーから読み込んでいる場合には可能な設定が異なりますし、アプリケーションの前段にリバースプロキシの Nginx などを設置している場合にはまた異なる設定が可能になります。
なので、ここでは上記どの場合でもおそらく有効な、Astro ミドルウェアを使った指定方法だけを紹介します。
frontend/src/middleware.ts
import { defineMiddleware } from "astro/middleware";
export const onRequest = defineMiddleware(async (context, next) => {
const response = await next();
const html = await response.text();
const isProd = import.meta.env.PROD;
if (isProd) {
response.headers.set(
"Cache-Control",
"public, max-age=60, s-maxage=300, stale-while-revalidate=180", // 値は適当です
);
}
return new Response(html, {
status: response.status,
headers: response.headers,
});
});
フロントエンドをエッジで動かすのはどう?
Astro をはじめ、モダンフロントエンドのウェブフレームワークは、大抵エッジランタイムでの動作をサポートしています。なのでエッジで動かすというのは良さげなアイデアに思えます。
…正直、試したことがないのでわかりません… Astro を Cloudflare Workers で動かして、DB に PlanetScale を使うとか、実に夢のある構成ではありますね。